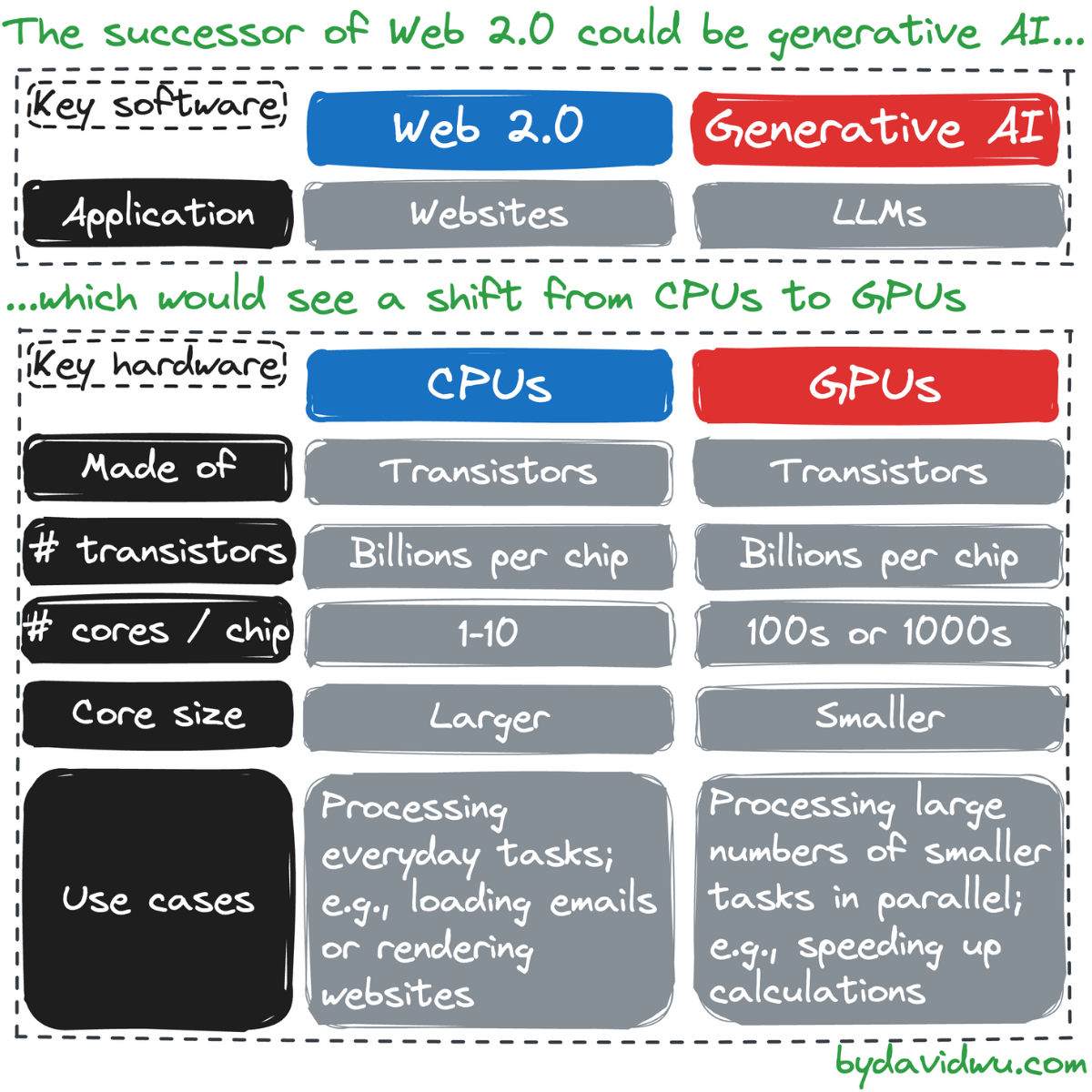
🌏 #2 | If Web 2.0 was powered by CPUs, generative AI will be powered by GPUs
💻 Web 2.0 to generative AI
Since the term Web 2.0 was coined in 1999, billions of people have gone online to talk to one another, share content, and buy and sell things.
As much as Web 2.0 was a software story about interactive websites, it was also a hardware story about computing devices getting faster and cheaper.
And the defining hardware component was the CPU, often considered the heart of a computer.
Generative AI is emerging as the successor to Web 2.0. The software story is defined by LLMs (large-language models), the AI models which underpin apps such as ChatGPT.
But the hardware heart of LLMs isn’t the CPU — it’s the GPU.
❓ CPUs versus GPUs
➡️ Similarities
CPUs and GPUs are both chips made up of transistors (silicon-based semiconductors). Modern chips are made up of billions of transistors, with more transistors meaning a faster device.
Crucially, the transistors on a chip are bundled together into cores, with each core able to concurrently handle tasks.
➡️ Differences
CPUs are made up of a smaller number of larger cores, typically countable using your fingers. In comparison, GPUs have hundreds or thousands of smaller cores.
The larger cores of CPUs make these chips a jack of all trades — and why CPUs are referred to as central processing units. They are suited for everyday tasks, from loading emails to rendering websites.
The smaller cores of GPUs are suited for handling large numbers of simpler tasks that can be done in parallel. These are not everyday tasks, but there are “killer use cases.” The first such use case was video game graphics — and so we refer to GPUs as graphics processing units.
✨ Video games to generative AI
The techniques used to accelerate graphics have gradually been adapted to speed up calculations in other areas, including computational chemistry and cryptocurrency mining.
But it’s the use of GPUs to develop (train) and operate (inference) LLMs that have emerged as the next killer use case.
🦙 Case study: Meta’s Llama models
In February 2023, Meta released the initial version of their Llama models, a collection of LLMs, with the most powerful 65-billion-parameter model having capabilities comparable to OpenAI’s GPT-3 model.
Training for this model was conducted over 21 days using 2048 Nvidia A100 GPUs, which can cost up to $15,000 each.
Remarkably, this is a fraction of the 16,000 GPUs that make up Meta’s AI Research SuperCluster.
💡 Why this matters
The shift to GPUs as the hardware heart of generative AI matters across the tech ecosystem:
📌 For big tech, GPUs are the next frontier of cloud.
📌 For startups, GPUs are a barrier to entry and present new problems to be solved.
📌 For governments, GPUs give rise to national security and environmental issues.
📌 For individuals, GPUs will drive demand for new skills, as we watch in awe.
✨ What did you think of this week's newsletter? Hit reply and let me know.
🙌 This newsletter is sent out to email subscribers on Monday and goes up on LinkedIn on Tuesday. If you see it in your feed, consider liking or reposting it.
📨 To ensure this newsletter doesn’t go into your spam folder, add me to your contacts.